What Are The Real Data Sources For Training LLMs?

Have you ever wondered where Generative AI models like OpenAI and LLaMa get their vast amounts of data to train their language models? It is no secret that these generative AI companies get it from public repositories and the internet.
The real question, however, is how on earth they scrape the entire internet - or at least that was my question. Surprisingly, it is simpler than you might imagine. In addition to the well-known sources like Wikipedia and Github that we are aware of, there are numerous other publicly accessible sources of data. We will examine the main data sources that make up the majority of the training data.
The Meta AI research paper titled "LLaMa: Open and Efficient Foundation Language Models" provides valuable information about the data sources used. Additionally, the data sources for GPT-3 are outlined in the GPT-3 Wikipedia page. The specific percentages of data utilized for training OpenAI and LLaMa are indicated in both Meta's research paper and GPT-3's Wikipedia entry.
- CommonCrawl
Common Crawl offers publicly available internet data accessible to all, aligning with its mission to democratize data and make it universally available.
Common Crawl has been collecting data since 2008, and the data is stored in Amazon S3. It has petabytes of data, and the most recent dataset available at the time of writing this article is May/June 2023
Percentage of DataSet for training the Models:
- OpenAI : 60% of training data
- LLaMa : 67% of training data - C4
C4 stands for Colossal Clean Crawled Corpus. It is a cleaned-up version of the Common Crawl Data set. The data cleaning process involved removing boiler-plate content, including menus, error messages and redundant text. C4 also filtered out offensive text, javascript related messages, and pages containing "lorem ipsum", as typically these pages are used as placeholders before a final copy is available.
Percentage of DataSet for training the Models:
- OpenAI : Not available
- LLaMa : 15% - GitHub
It is the largest cloud-based platform to manage and store developers' code. According to Wikipedia as of June 2023, GitHub had 100 million developers and 372 millions repositories. It is no wonder that the LLM models can be trained with this vast amount of data.
Percentage of DataSet for training the Models:
- OpenAI : Not available
- LLaMa : 4.5% - Wikipedia
It is a vast and diverse online encyclopedia that contains a massive amount of information across various domains, including Biology & Health Sciences, Geography, History, Biography, Society, Culture & Arts and more
As of July 2023, Wikipedia contained 4.3 billion words, spanning about 58,624,755 pages. The size of all the compressed articles was approximately 22.14 GB without media.
Percentage of DataSet for training the Models:
- OpenAI : 3% of data
- LLaMa : 4.5% - Books
The books dataset was introduced by Zhu et al. in their work Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. It comprises approximately 11,000 indie books scraped from the internet. The sources for Books1 and Books2 are not known. If you are interested in a dataset similar to books, a good source is the Hugging Face bookcorpusopen.
Percentage of DataSet for training the Models:
- OpenAI : 16% from Books1 and Books2
- LLaMa : 4% from all Books, most likely BookCorpus. - ArXiv
ArXiv is a service that provides free distribution and serves as an open-access archive for over 2 million scholarly articles. It is maintained and operated by Cornell University.
These articles cover various disciplines such as physics, mathematics, computer science, biology, finance, statistics, engineering, systems science, and economics. It's important to note that the materials available on ArXiv are not peer-reviewed by the platform itself.
Percentage of DataSet for training the Models:
- OpenAI : Not available
- LLaMa : 2.5% - StackExchange
It is a network of 181 communities that have questions and answers on different topics. The topics include technology, culture & creation, life & arts, science, professional and business. The breadth of the topics which encompassed 3.1 million questions and about 3.5 million answers, makes it a great source of data for LLMs.
Percentage of DataSet for training the Models:
- OpenAI : Not Available
- LLaMa : 2%
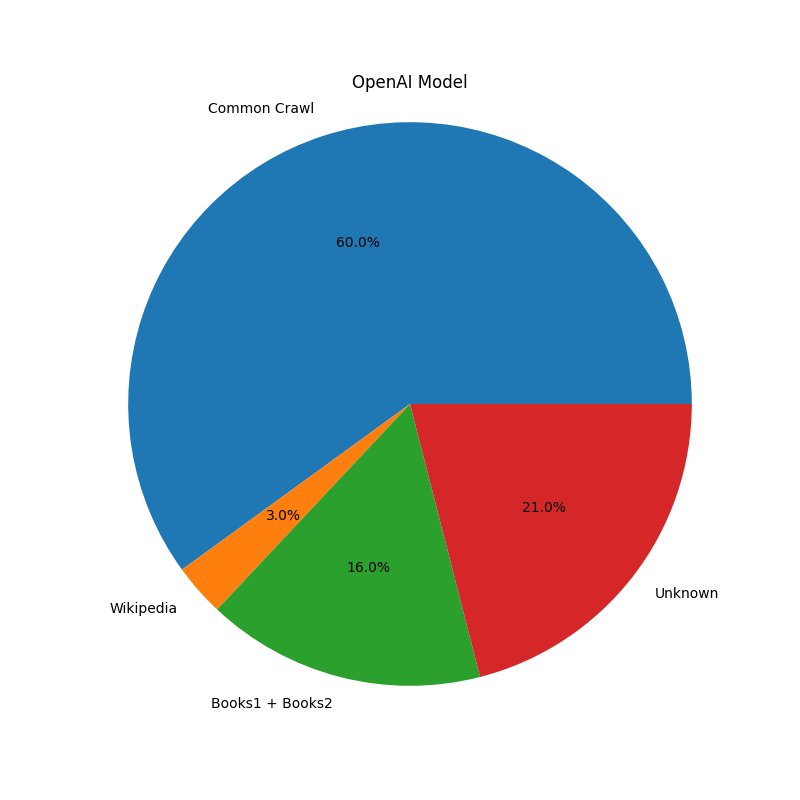
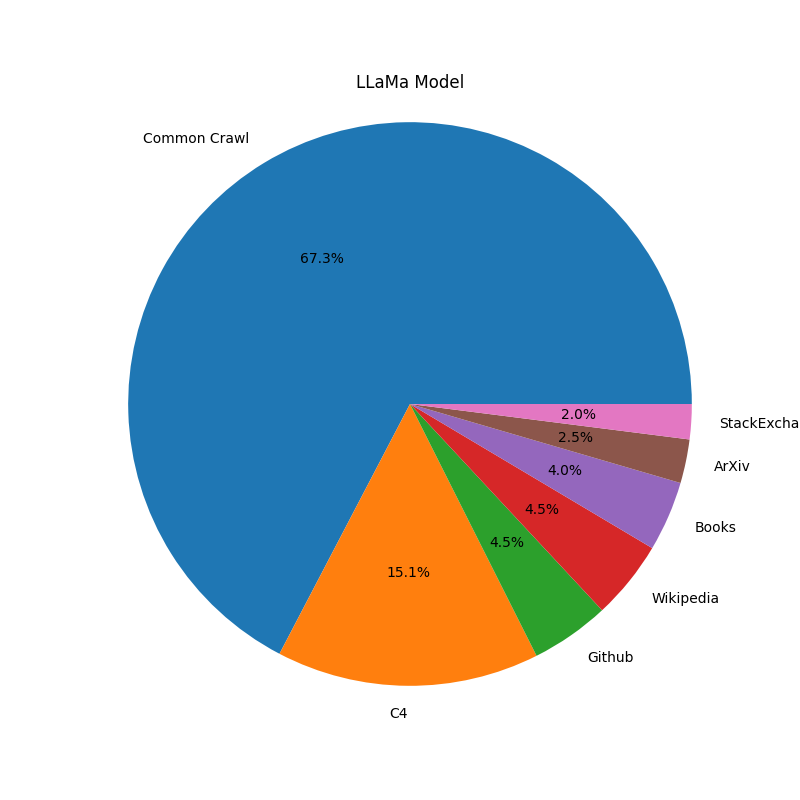
OpenAI and LLaMa model Data Sources
The data sources shown above constitute a significant portion of the data used to train LLMs. However it is highly likely that generative AI companies also scrape the internet for niche data sources. Social media platforms such as Facebook, Instagram, Snapchat, Stack Overflow, Reddit, Quora, among others serve as valuable sources of information. The crucial question is whether these sources permit the use of their data for LLMs, and some may not make it available for others. Why would Facebook(Meta) give OpenAI the access to facebook data when it has its own generative AI story to tell?
Several open-source generative AI LLMs also exist, and one of them is BLOOM (Big Science Large Open-Science Open-access Multilingual Language Model). This collaborative effort involved 1000 AI researchers who generously made it accessible to the public. While its success is yet to unfold, I, for one, am personally cheering for the triumph of an open-source LLM.